

Histone PHP Database
Histone est un système de gestion de base de donnée rustique sous forme de fichiers que j'ai créé à l'origine pour être intégré dans le CMS Plasmide. Intégralement ecrit en PHP, il ne nécessite pas de module ou de lib externe.
Depuis le temps que je m'en sers pour tout un tas de projets, je me suis dit que ça pourrait être utile à d'autres allergiques au SQL 😁. Histone est donc disponible en license libre (GNU AGPLv3) .

Le projet
La génèse
Histone a été developpé à ses débuts en 2008 pour fonctionner sur un serveur NAS DNS-313 de D-Link modifié (CPU 300 MHz, 64Mo de RAM, le tout sous debian 4). Il fait moins de 20 Ko. Il est donc concu pour être trés économe en ressource et peut fonctionner sur des petits systèmes embarqués.
Il est vrai qu'a l'ère du tout centralisé et du cloud, il peut paraitre étonnant de concevoir un système de persistance sous forme de fichiers un peu "à l'ancienne". Il y a deux raison a cela.
La premiere est que j'utilise pour la plupart de mes projet des petites machine, qui bien que performantes, n'ont pas les capacités des gros serveurs dédiés à des taches d'hébergement. Un systeme de gestion de base de données (SGBD) tel que MySQL est trop gourmand pour de telles configurations.
La seconde vient du fait que j'ai pu observé que la plupart du temps, lorqu'un SGBD est installé sur une machine, il ne sert que pour l'unique site web hebergé sur la même machine.
Malgres mes recherches, je n'ai trouvé, à l'époque, aucun systeme de persistances des données suffisamment optimisé pour de telles contraintes. Il existait bien quelques bibliotheques PHP pour manipuler des fichiers XML, mais les temps d'acces explosaient quand il commençait à y avoir plusieurs milliers d'enregistrements.
Les caractéristiques
Histone fonctionne sur quelques principes simples :
- Que du PHP "vanilla", pas de lib externe, ni de module, ni de
ces abominations deframeworks. - Pas de langage de requêtes compliqué, type SQL, tout se fait en orienté objet.
- Les données sont stockées dans des fichiers PHP natif, pour profiter de la gestion du cache du Zend Engine.
- Un champ "id" en clé primaire par table qui est un nombre (Integer) et auto incrémental. Et c'est tout.
- Autant de clé étrangères qu'on veut, déclarées dans un fichier "structure.php" dédié à chaque table.
- Les modules de cache de type APCu sont géré automatiquement, ce qui augmente encore les perfs en lecture.
- Pas de jointure ou de vues. La logique est a implémenter dans le code applicatif.
Pour donner une idée de ses performances, il a servi de base de donnée à plusieurs sites sur ce fameux DNS-313 cité plus haut pendants plusieurs années (avant que le raspberry pi n'existe), dont un des site contenait un forum avec plusieurs milliers de posts. Les temps de réponses ne depassaient jamais les 300 millisecondes.
Envie de tester ? C'est parti !
Télécharger
Voici le lien de téléchargement : Histone
Installation
Décompression
Apres avoir téléchargé le fichier ZIP, décompresse le à la racine de ton site. Tu peux ensuite supprimer le fichier ZIP, il ne sera plus utile. Une fois décompréssé tu dois avoir une arboresence comme celle ci :
- core
- model
- Archivable.php
- Archivist.php
- Cache_helper.php
- Ribosome.php
- model
- local
- data
Création de la base
Pour creer une nouvelle table dans la base de donnée, il suffit simplement de créer un dossier portant le nom voulu dans le dossier data. Dans ce dossier il faut creer un fichier structure.php qui permet de renseigner les éventuelles clé étrangères. Toutes les tables ont automatiquement un champ ID qui est auto incrémental.
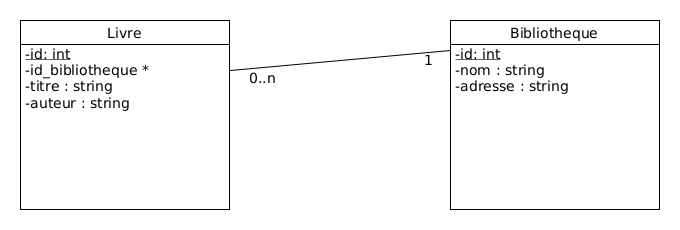
Exemple avec cas d'usage : livres et bibliothèques
Je veux créer la table Livre et la table Bibliothèque.
On aura donc :
- core
- model
- Archivable.php
- Archivist.php
- Cache_helper.php
- Ribosome.php
- model
- local
- data
- Livre
- strucure.php
- Bibilotheque
- structure.php
- Livre
- data
Un livre appartient à une seule bibliothèque, mais une bibliothèque peut contenir plusieurs livres. On aura donc une relation de 1-n, matérialisée par une clé étrangère dans la table livre que j'appelerais id_bibliotheque.
Une fois n'est pas coutume, modélisé en UML ca nous donne :
Une fois les deux dossier créés, édite les fichiers structures pour configurer les clés étrangères.
Pour Livre :
<?php
$structure = ['id_bibliotheque'];
?>
Pour Bibliotheque :
<?php
$structure = [];
?>
Le fichier est obligatoire, même si la table n'a pas de clé étrangères.
Le nom des clé étrangèress est libre. La declaration des clé étrangères de cette facon permet d'optimiser drastiquement les acces aux données.
Utilisation
Importation des ressouces
Tout d'abord il faut importer les differents fichiers :
<?php
include('core/model/Cache_helper.php');
include('core/model/Ribosome.php');
include('core/model/Archivist.php');
include('core/model/Archivable.php');
?>
Ensuite il faut créé un objet d'acces à la base de donnée
<?php
$arch = new Archivist();
?>
Pour finir il faut creer un objet qui va representer une entrée dans la base de donnée. Il est imperatif de préciser le nom de la table lorsque l'on créée un Archivable.
<?php
$livre = new Archivable("Livre");
?>
Maintenant que tu as les bases, passons aux choses serieuses : les requetes dans la base de donnée.
Insertion
On commence par renseigner les attributs à sauvegarder, cela se fait par la méthode set(String nomAttribut, String/int valeurAttribut) de l'objet Archivable. Puis on l'ajout à la base de donnée avec la methode archive(Archivable object) de l'Archiviste.
<?php
$arch = new Archivist();
$livre = new Archivable("Livre");
$livre->set('titre', 'De la brièveté de la vie');
$livre->set('auteur', 'Sénèque');
$id = $arch->archive($livre);
echo('Livre ajoué avec l\'id : '.$id );
// on peut en ajouter un autre en creant un nouveau Archivable de type livre
$livre = new Archivable("Livre");
$livre->set('titre', 'De la vie heureuse');
$livre->set('auteur', 'Sénèque');
$arch->archive($livre);
?>
Simple non ?
Petite précision, les champs/colonnes d'une table sont créé dynamiquement en fonction des objets qui sont ajoutés ou supprimés. Toutes les tables disposent en outre d'un identifiant unique 'id' par enregistrement, mais pas besoin de te tracasser avec sa gestion, il est créé et auto incrémenté lors de l'insertion d'une nouvelle entrée.
Selection
Ce coup ci on va utiliser la methode restore(Archivable $archivable) de l'Archiviste. Cette methode renvoi un tableau contenant les entrées trouvés ou un tableau vide si rien ne correspont.
<?php
//Création d'un objet Archivable qui va permettre de requeter la table Livre
$livres_à_trouver = new Archivable('Livre');
//Je vais récuperer tous les livres dont l'auteur s'appelle exactement Sénèque
$livres_à_trouver->set('auteur', 'Sénèque');
//les objets trouvés sont renvoyé sous forme d'un tableau d'Archivables
$livres_trouvés = $arch->restore($livres_à_trouver);
// on peut verifier qu'on a bien trouvé des livres. Comme ceci par ex:
if(empty($livres_trouvés)){
//si la liste est vide on l'indique
echo('aucun livre trouvé.')
//et on quitte qvant d'executer la boucle qui suit (à replacer par un return dans une fonction).
exit(0)
}
// on peut afficher les archivables trouvé de cette manière
foreach($livres_trouvés as $livre){
echo(' Livre trouvé : '.$livre->get('titre').' écrit par '.$livre->get('auteur').' avec id automatique : '.$livre->get('id'));
}
?>
Pour faire un recherche approximative maintenant, on va plutot utiliser la methode search(Archivable $archivable)
<?php
$livres_à_trouver = new Archivable('Livre');
$livres_à_trouver->set('titre', 'la vie');
$livres_trouvés = $arch->search($livres_à_trouver);
// Et on affiche les livres trouvés
foreach($livres_trouvés as $livre){
echo(' Livre trouvé : '.$livre->get('titre').' écrit par '.$livre->get('auteur'));
}
?>
Modification
Pour faire une modification, on utilise deux objets Arhivable. Le premier sert à faire une recherche, de la même manière que la fonction restore. Le deuxieme contient les attributs à modifier ou à ajouter.
<?php
$livres_à_trouver = new Archivable('Livre');
$livres_à_trouver->set('auteur', 'Sénèque');
$livre_modifié = new Archivable('Livre');
$livre_modifié->set('auteur', 'Lucius Annaeus Seneca');
$arch->update($livres_à_trouver, $livre_modifié);
?>
Suppression
Pour faire une suppression, le principe et le même que pour une selection.
<?php
# pour supprimer tous les livres dont l'auteur est Sénèque
$livres_à_supprimer = new Archivable('Livre');
$livres_à_supprimer->set('auteur', 'Sénèque');
$arch->delete($livres_à_supprimer);
# Pour supprimer Le livre dont l'id est 1
$livre_à_supprimer = new Archivable('Livre');
$livre_à_supprimer->set('id', 1);
$arch->delete($livre_à_supprimer);
?>
Les petits plus Histone
Le tri
Il est possible également de demander à l'archiviste de trier les donnée avant de les afficher:
<?php
# On récupere tous les livres
$livres_à_trouver = new Archivable('Livre');
$liste_livres = $arch->restore($livres_à_trouver);
# Trie les livre par titre et par ordre alphabetique avec le troisième argument à true
$liste_livres = $arch->sort($liste_livres, 'titre', true);
# Trie les livre par auteur et par ordre alphabetique inverse avec le troisième argument à false
$liste_livres = $arch->sort($liste_livres, 'auteur', false);
// Et on affiche les livres trouvés et triés
foreach($liste_livres as $livre){
echo(' Livre trouvé : '.$livre->get('titre').' écrit par '.$livre->get('auteur'));
}
?>
L'implementation de ArrayAccess
Les objets archivable implementent l'interface ArrayAccess. Il est donc possible de les utiliser comme un tableau à une dimension.
<?php
$livre_à_trouver = new Archivable('Livre');
$livre_à_trouver['auteur'] = 'Sénèque';
$livre_à_trouver['titre'] = 'De la vie heureuse';
$liste_livres = $arch->restore($livres_à_trouver);
// Et on affiche les livres trouvés et triés
foreach($liste_livres as $livre){
echo(' Livre trouvé : '.$livre['titre'].' écrit par '.$livre['auteur']);
}
?>
Le but est d'alleger un peu le code de l'accès aux attributs des objets archivables.
La recherche unique
Il est possible de recuperer seulement le premier Archivable qui correspond à un critère précis. C'est utile lors d'une requete sur un objet qu'on sait être unique.
<?php
$livre_à_trouver = new Archivable('Livre');
$livre_à_trouver['id'] = 1;
$livre_trouvé = $arch->restore_first($livres_à_trouver);
// on peut verifier qu'on a bien trouvé des livres. Comme ceci par ex:
if(empty($livre_trouvé)){
//si livre_trouvé est vide ou égale à NULL ou à false .
echo('aucun livre trouvé.')
//et on quitte qvant d'executer la suite (à replacer par un return dans une fonction)
exit(0)
}
// ici on s'évite une boucle fastidieuse
echo(' Livre trouvé : '.$livre_trouvé['titre'].' écrit par '.$livre_trouvé['auteur']);
?>
Contribuer
Tu peux contribuer à l'amélioration d'Histone en m'envoyant des patch/diff, il est open source (license AGPLv3).